
July 2022 in review
This is the first edition of what I intend to be a monthly round-up of the month. I’m doing this a bit for you — to keep tabs on what I’m up to — and also a bit for me to reflect on where my focus and effort are.FN
Doing the work
I started the month wrapping up basic GitHub Checks integration for Times Square, a dynamic Jupyter notebook publishing service for the Rubin Science Platform. Times Square is in semi-stealth mode (they’re both currently public open source), but I can’t wait to see how they get used by Rubin teams.
Next, I spent some time working on a new Cookiecutter template for “SQuaRE-style” Python packages that are published to PyPI. We’ve been informally copying the same patterns between our major libraries like Safir and Documenteer, but this template formalizes the basic structure for a SQuaRE package. It also provided us a chance to update our best practices. For instance, we’ve switched to pyproject.toml entirely for project metadata, as I wrote about on this blog. Second, I wanted to find a way to make our common GitHub Actions workflows more maintainable. It turns out that composite GitHub Actions are a low-overhead way of grouping sequences of actions together. The result is that the “user” workflows are both shorter and have less code to maintain since all the logic is now maintained in centralized actions. So far I’ve made three composite actions: lsst-sqre/run-tox, lsst-sqre/ltd-upload, and lsst-sqre/build-and-publish-to-pypi.
I refreshed some of the Kafka infrastructure that SQuaRE uses internally and provides to the rest of Rubin Observatory. First, I updated the packaging for Kafkit, our Python package for encoding Kafka messages in conjunction with the Confluent Schema Registry. Kafkit is also available on conda-forge now at conda-forge/kafkit-feedstock. I also overhauled Strimzi Registry Operator, our Kubernetes operator for deploying the Confluence Schema Registry on a Strimzi-deployed Kafka cluster. One bit of that refresh I’m really happy with is a PR that deploys Kafka, the operator, and a Schema Registry in minikube within GitHub Actions. This technique for building an application within minikube has a lot of potential as way of running integration tests for a lot of our microservices.
Lastly, I’ve also been thinking more about my online presence, including the viability of Instagram and my years-long absence from Twitter. I’ve started to invest effort into Micro.blog as a way of owning my content and cross-posting to Twitter and Instagram where it makes sense. Social media was really important for launching my career, but while working Rubin I’ve let it all drop off. It feel like it’s time to re-emerge, but on my own terms. I feel like we’re doing a lot of cool stuff at Rubin, and it’s time to share it with the world now that we’re getting closer to first light.
Pursuits
I got a DJI Mini 3 micro drone. The technology is astounding. I’ve been steadily learning its flying functionality and just barely digging into its camera functionality. I’m also playing around with editing the drone footage on my iPad with LumaFusion. It really feels like the future.
Reading
Finished The Cartographers by Peng Shepherd and Tongues of Serpents by Naomi Novik (with Amanda). Started reading Hard-Boiled Wonderland and the End of the World by Haruki Murakami.
Heavy rotation
The Garden by Basia Bulat (we’ve been playing this on vinyl at dinner), Formentera by Metric, and graves by Purity Ring.
Strimzi Registry Operator 0.5.0 released for Kafka
We just released version 0.5.0 of the Strimzi Registry Operator (see release notes). Strimzi Registry Operator helps you run a Confluent Schema Registry for a Kafka cluster that’s managed by the fabulous Strimzi operator for Kubernetes. The Schema Registry allows you to efficiently encode your Kafka messages in Avro, while centrally managing their schemas in the registry.
With the Strimzi Registry Operator, you deploy a Kubernetes resources like this:
apiVersion: roundtable.lsst.codes/v1beta1
kind: StrimziSchemaRegistry
metadata:
name: confluent-schema-registry
spec:
listener: tls
securityProtocol: tls
compatibilityLevel: forward
The operator deploys a Schema Registry server based on that StrimziSchemaRegistry resource and takes care of details like mapping the Kafka listener and converting the mutual TLS certificates into the JKS formatted keystore and truststore required by the Schema Registry.
We at Rubin Observatory’s SQuaRE team created the Strimzi Registry Operator back in 2019 to help us deploy an internal Kafka to power our ChatOps. Since then, this technology has become critical for other Rubin applications like the alert broker and the engineering facilities database (telemetry from the telescope facility). We’ve also gotten hints that the operator has been adopted by other Strimzi users, which we’re thrilled to hear of. Open source in action! ✨
To learn more, take a look at the Strimzi Registry Operator repository on GitHub.
A little father-daughter woodworking moment. 🐱🪚 Emma likes shavings… especially the long stringy ones from rounding off edges.

TIL you can create Note and warning admonitions in GitHub Flavored Markdown
httpie and GitHub Actions
I love httpie as an alternative to curl. It feels fresher, and is built for working with today’s HTTP APIs.
Anyways, I was using httpie’s @= feature for embedding file content in a JSON field within a GitHub Actions workflow and got an error:
Request body (from stdin, –raw or a file) and request data (key=value) cannot be mixed. Pass –ignore-stdin to let key/value take priority. See https://httpie.io/docs#scripting for details.
I didn’t think I was doing anything with passing standard input, and the command was running just fine locally, so I spent a good while finding possible solutions. Turns out I should have taken the error at face value. Somehow GitHub Actions runs commands in a way that triggers this stdin behaviour and need --ignore-stdin:
http --ignore-stdin --json post $REGISTRY_URL/subjects/testsubject/versions \
schema=@testsubject.json \
Accept:application/vnd.schemaregistry.v1+json
The fact is that one of America’s two major political parties appears to be viscerally opposed to any policy that seems to serve the public good.
Embracing the pyproject.toml future of packaging Python projects with setuptools
Last week I worked on a new template for PyPI python projects for SQuaRE, my team at Rubin Observatory.1 One of the banner features in this new template is that we did away with setup.cfg and went all-in with pyproject.toml for defining our projects’ packaging.
PEPs 517, 518 and 621
First, a reminder of what’s going on with Python packaging. PEP 517 and PEP 518 introduced the idea of a “build-system independent format for source trees.” Up to that point, the assumption was that all Python projects would be built with setuptools.2 A build-system independent format lets you specify an alternative build backend, but in a standardized way, so that a front-end like pip can build and install the package regardless. In the SQuaRE team, though we use setuptools, we embraced PEP 517 and added pyroject.toml files containing a [build-system] table. However, our project metadata remained in setup.cfg, where setuptools expects it.
Then in PEP 621, Python introduced a standardized schema for storing a project’s metadata (everything from its name to its dependencies) in a [project] table of project.toml files. At this point, it seemed as if we could finally drop setup.cfg files from our projects entirely.
Well, almost. The last straw was for setuptools itself to support pyproject.toml configurations for aspects of the build that are specific to setuptools, like package discovery. Currently, the support for a [tool.setuptools] table in pyproject.toml is in beta, but it exists and that was good enough for our team to start supporting it.
And with that, we can now package our Python projects with only a pyproject.toml file, dropping setup.cfg and (almost) setup.py (more on this later).
Our template pyproject.toml
This is the example pyproject.toml from our template (and here’s the related Jinja2/cookiecutter template for it). You can also see it in action with Kafkit, one of our Python packages for Kafka.
[project]
# https://packaging.python.org/en/latest/specifications/declaring-project-metadata/
name = "example"
description = "Short one-sentence description of the package"
license = {file = "LICENSE"}
readme= "README.md"
keywords = [
"rubin",
"lsst",
]
# https://pypi.org/classifiers/
classifiers = [
"Development Status :: 4 - Beta",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Intended Audience :: Developers",
"Natural Language :: English",
"Operating System :: POSIX",
"Typing :: Typed",
]
requires-python = ">=3.8"
dependencies = []
dynamic = ["version"]
[project.optional-dependencies]
dev = [
# Testing
"coverage[toml]",
"pytest",
"pytest-asyncio",
"pre-commit",
"mypy",
# Documentation
"sphinx",
"documenteer",
"lsst-sphinx-bootstrap-theme",
"sphinx-prompt",
"sphinx-automodapi",
"myst-parser",
"markdown-it-py[linkify]",
]
[project.urls]
# Homepage = "https://example.lsst.io"
Source = "https://github.com/lsst-sqre/example"
[build-system]
requires = [
"setuptools>=61",
"wheel",
"setuptools_scm[toml]>=6.2"
]
build-backend = "setuptools.build_meta"
[tool.setuptools_scm]
[tool.setuptools.packages.find]
# https://setuptools.pypa.io/en/latest/userguide/pyproject_config.html
where = ["src"]
include = ["example*"]
[tool.coverage.run]
parallel = true
branch = true
source = ["example"]
[tool.coverage.paths]
source = ["src", ".tox/*/site-packages"]
[tool.coverage.report]
show_missing = true
exclude_lines = [
"pragma: no cover",
"def __repr__",
"if self.debug:",
"if settings.DEBUG",
"raise AssertionError",
"raise NotImplementedError",
"if 0:",
"if __name__ == .__main__.:",
"if TYPE_CHECKING:"
]
[tool.black]
line-length = 79
target-version = ["py38"]
exclude = '''
/(
\.eggs
| \.git
| \.mypy_cache
| \.tox
| \.venv
| _build
| build
| dist
)/
'
# Use single-quoted strings so TOML treats the string like a Python r-string
# Multi-line strings are implicitly treated by black as regular expressions
[tool.pydocstyle]
# Reference: http://www.pydocstyle.org/en/stable/error_codes.html
convention = "numpy"
add_select = [
"D212" # Multi-line docstring summary should start at the first line
]
add-ignore = [
"D105", # Missing docstring in magic method
"D102", # Missing docstring in public method (needed for docstring inheritance)
"D100", # Missing docstring in public module
# Below are required to allow multi-line summaries.
"D200", # One-line docstring should fit on one line with quotes
"D205", # 1 blank line required between summary line and description
"D400", # First line should end with a period
# Properties shouldn't be written in imperative mode. This will be fixed
# post 6.1.1, see https://github.com/PyCQA/pydocstyle/pull/546
"D401",
]
[tool.isort]
profile = "black"
line_length = 79
known_first_party = ["example", "tests"]
skip = ["docs/conf.py"]
[tool.pytest.ini_options]
asyncio_mode = "strict"
python_files = [
"tests/*.py",
"tests/*/*.py"
]
[tool.mypy]
disallow_untyped_defs = true
disallow_incomplete_defs = true
ignore_missing_imports = true
strict_equality = true
warn_redundant_casts = true
warn_unreachable = true
warn_unused_ignores = true
# plugins =
This pyproject.toml is built for a “src/” Python package layout. The [tool.setuptools.packages.find] table is where we configure this.
setup.py is still necessary, for now
Our original goal with this new template was to do away with the “legacy” packaging files: setup.cfg and setup.py. We did succeed in doing away with setup.cfg since not only has setuptools moved to pyproject.toml, but nearly every other tool using setup.cfg has moved their configurations as well.3
It might seem like setup.py is also obsolete. However, in our experience, some projects still require it for editable installs pip install -e .. We often use editable installs during development to rapidly test and prototype, so this is a useful feature for us. For that reason, we’ve had to re-add a basic setup.py file to our projects:
from setuptools import setup
setup()
What’s surprising is that, anecdotally, not all setuptools-based projects seem to need a setup.py for their editable installs.
Regardless, setuptools issue 2816 is worth a subscription to learn when this has changed.
Concatenated READMEs with Markdown may not work
With the new [project] table in pyproject.toml, you can set a readme field that links to your project’s README file. This effectively replaces the old “long description” field, where, back in the setup.py days, we’d write a small function to open and insert text from the README file. This is a nice, clean way of standardizing that practice.
Something I liked to do in our setup.cfg files was to actually concatenated multiple files into the long description:
[metadata]
name = documenteer
long_description = file: README.rst, CHANGELOG.rst, LICENSE
long_description_content_type = text/x-rst
This way, the project’s page on PyPI would include not only the README but also the change log, followed by the license. Nice.
In pyproject.toml, the same can be accomplished by making the README dynamic:
[project]
dynamic = ["readme"]
[tool.setuptools.dynamic]
readme = {file = ["README.rst", "CHANGELOG.rst"]}
And this works. Where things went wrong for me is using Markdown for the README and CHANGELOG:
[project]
dynamic = ["readme"]
[tool.setuptools.dynamic]
readme = {file = ["README.md", "CHANGELOG.md"]}
When I looked inside the built wheel’s METADATA file, the Description-Content-Type would be text/re-structured-text instead of text/markdown. Normally, the tooling successfully detects the content type for the description, but this may not be working for dynamic READMEs. Something to be aware of, as setuptools’ pyproject.toml support is being developed.
Further reading
- PyPA’s documentation for declaring project metadata in pyproject.toml
- setuptools’ documentation for pyproject.toml configuration
-
We love to create templates because they enable us to standardize on technologies and workflows. Even though we have tens/hundreds of GitHub repositories at Rubin (depending on the organizational scope), working in these projects is familiar because they all share the same structure and technologies. ↩︎
-
Like distutils and packaging — remember thee? ↩︎
-
Except flake8 — so we’ve booted flake8 to its own
.flake8configuration file. ↩︎
The Penetanguishene outer harbour last night, dressed up in the setting light.

Onboarding into a public cloud project: enter your email and credit card info (or have your team lead click an invite button).
Onboarding into a gov “cloud” project: send us your detailed CV, passport scan, visa, and other personal info.

Finished reading: The Cartographers: A Novel by Peng Shepherd 📚
I loved this book so much, and am glad I learned about it by chance from @manton’s feed. It’s an academic thriller — what can I say! I won’t think about maps the same again.
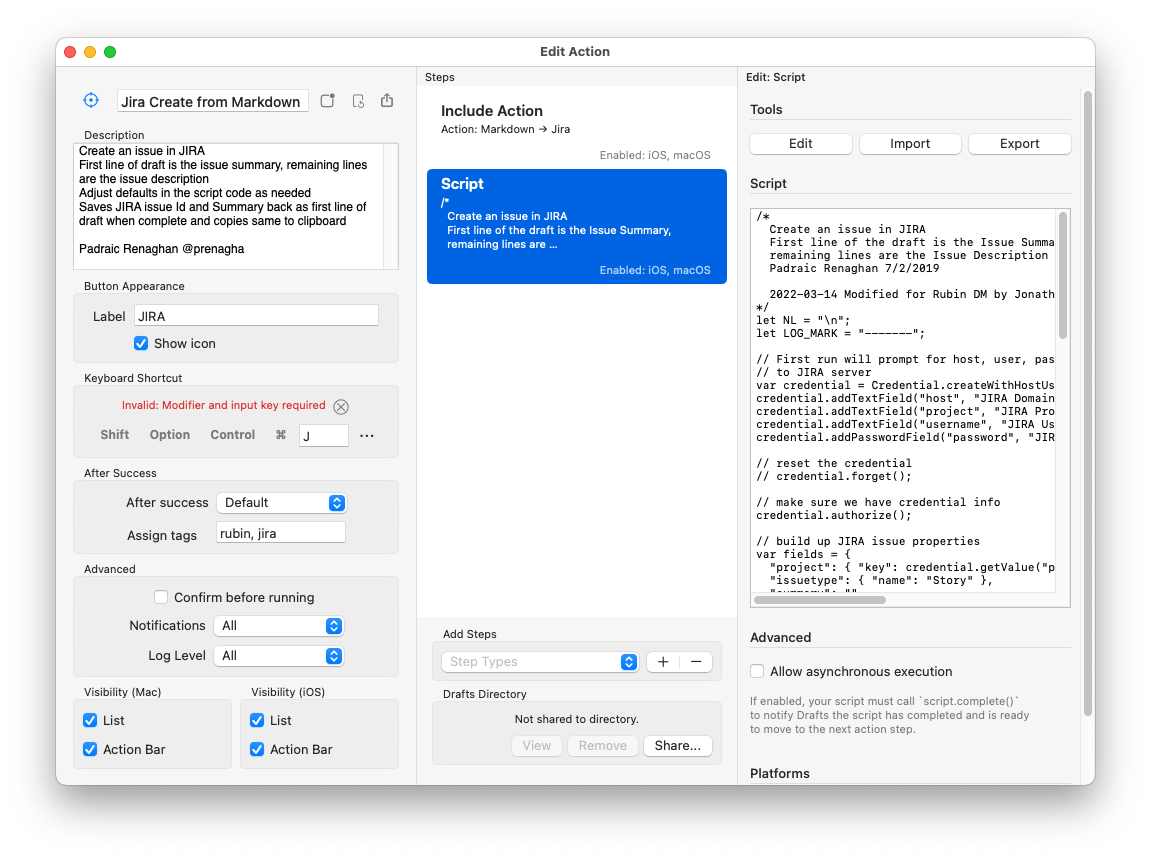
Jira can be rough compared to GitHub issues; but it’s the backbone of Rubin work tracking. I’ve discovered how to use @draftsapp for Mac/iPad/iOS to submit issues for me: it converts Markdown to Jira, creates the issue in my current epic, and then prepends a link to my draft 🥳
I’ve been reading Architecture Patterns with Python. Every chapter they introduce a new issue, and I’m like “yes, that’s an architectural problem I’ve had in my code” and then they show to solve it. Highly approachable. I recommend it to anyone building applications or services.
I’ve been using Pydantic and FastAPI a lot lately and I’m struck at their lack of API docs (compared to most Python package docs). Its as if these modern libraries are built for the era of IntelleSense and autocomplete to bring docs into the editor.
Rethinking the social web in 2021
Facebook was fantastic as a college kid: it was just an exclusive club for your an your dorm mates. Then everyone got on Facebook and the content became less and less relevant. Twitter was fantastic as a way to connect with techy astronomy colleagues. It felt like our own little back channel. Then Twitter became a political battle ground, and although the conversations were powerful, they were also overwhelming. Instagram was an oasis where there was no politics, just photos of your day. A way to connect with faraway friends. Now Instagram has become Skymall. Does the utility of all social media platforms self-implode at some point under the weight of growth and ad sales?
I feel like I’ve lost the tune with social media. I haven’t used Facebook or kept up with my Twitter timeline in years. I keep feeling bad whenever I open Instagram. And that’s fine. I have more time for meaningful work. But I also feel like I’m disappearing off the face of the internet by no longer engaging with social media.
So here we are in 2021. What should my social existence on the web look like?
I’m going to try going back to the basics. I’m going to resolve to own my own corner of the web with jonathansick.ca and no longer rent space from social media companies. I’m also going to see how this micro.blog site fits in. I initially signed up in 2017. The concept of the indie web didn’t fully connect with me back then, but now its clear that building my own site and paying directly for services and apps is the way that I want to exist on the web going forward.